Pandas установка значения столбца на основе значений из другого столбца
Дня начала сделаем небольшой датафрейм при помощи метода .from_dict ():
import pandas as pd
import numpy as np
df = pd.DataFrame.from_dict(
{
'Name': ['Jane', 'Melissa', 'John', 'Matt'],
'Age': [23, 45, 35, 64],
'Birth City': ['London', 'Paris', 'Toronto', 'Atlanta'],
'Gender': ['F', 'F', 'M', 'M']
}
)
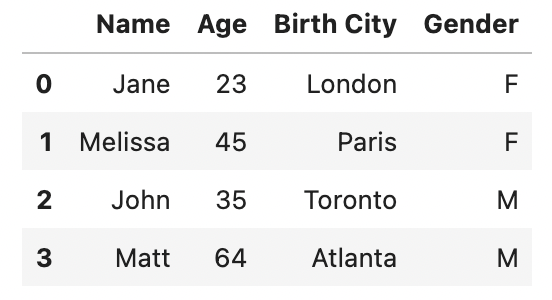
И посмотрим, что есть в данном датафрейме
df
Использование Pandas.loc для установки столбца в Pandas
Функция Pandas.loc невероятно мощная! Вот очень хорошая статья по loc с разбором данной функции. Pandas loc создает булеву маску на основе условия. Иногда этим условием может быть просто выбор строк и столбцов, но его также можно использовать для фильтрации данных. К этим отфильтрованным рамкам данных могут быть применены значения.
Cинтаксис:
df.loc[df['column'] condition, 'new column name'] = 'value if condition is met'
Используя синтаксис выше, мы фильтруем датафрейм с помощью .loc, а затем присваиваем значение любой строке в столбце (или столбцах), где выполняется условие.
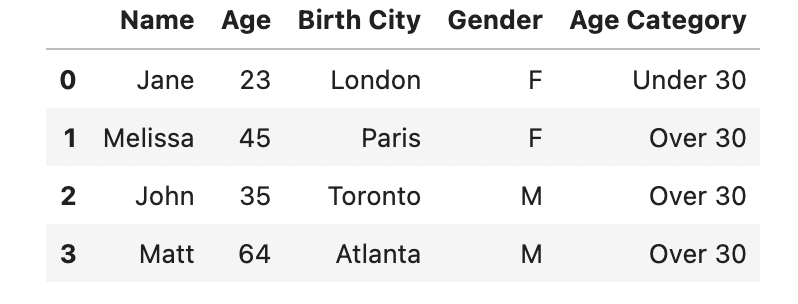
Давайте попробуем это сделать — присвоив строку 'Under 30' всем, чей возраст меньше 30 лет, а 'Over 30' — всем, кому 30 или больше:
df['Age Category'] = 'Over 30'
df.loc[df['Age'] < 30, 'Age Category'] = 'Under 30'
Результат:
Давайте посмотрим, что мы сделали:
- Мы присвоили строку 'Over 30' каждой записи в датафрейме.
- Затем мы используем .loc для создания булевой маски на столбце Age, чтобы отфильтровать строки, в которых возраст меньше 30 лет. Когда это условие выполняется, столбцу Возрастная категория присваивается новое значение 'Under 30'.
Но что происходит, когда у вас несколько условий? Можно, конечно, использовать .loc несколько раз, но это сложно для чтения и довольно неприятно для написания. Давайте посмотрим, как это можно сделать с помощью метода numpy.select ().
Использование Numpy Select для установки значений с помощью нескольких условий
Аналогично описанному выше методу использования .loc для создания условного столбца в Pandas, мы можем использовать метод numpy .select ().
Теперь, допустим, мы хотим применить несколько различных возрастных групп, как показано ниже:
- <20 years old,
- 20-39 years old,
- 40-59 years old,
- 60+ years old
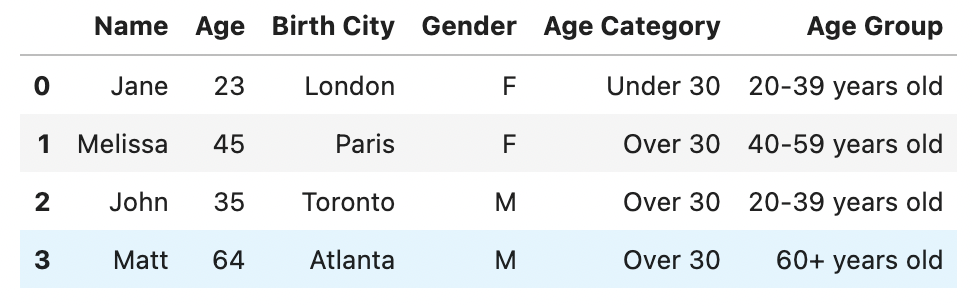
Для этого создадим список условий и соответствующих значений для заполнения:
conditions = [
(df['Age'] < 20),
(df['Age'] >= 20) & (df['Age'] < 40),
(df['Age'] >= 40) & (df['Age'] < 59),
(df['Age'] >= 60)
]
values = ['<20 years old', '20-39 years old', '40-59 years old', '60+ years old']
df['Age Group'] = np.select(conditions, values)
Результат:
Давайте разберем, что происходит:
- Сначала мы определяем список условий, в котором указаны критерии. Следует отметить, что списки являются упорядоченными, то есть они должны располагаться в том порядке, в котором вы хотели бы видеть соответствующие значения.
- Затем мы определяем список значений, который соответствует значениям, которые вы хотели бы применить в новом столбце.
Я в своей обычной практике использую именно эти методы, вот статья в которой еще рассмотрены варианты с Apply и Map
Ошибка ValueError: Cannot mask with non-boolean array containing NA / NaN values
Итогда при работе с данными возникает ошибка: ValueError: Cannot mask with non-boolean array containing NA / NaN values, как ее исправить можно посмотреть в этой статье — https://appdividend.com/2023/01/29/cannot-mask-with-non-boolean-array-containing-na-nan-values/