Pandas встановлення значення стовпця на основі значень з іншого стовпця
Дня початку зробимо невеликий датафрейм за допомогою методу .from_dict ():
import pandas as pd import numpy as np
df = pd.DataFrame.from_dict(
{
'Name': ['Jane', 'Melissa', 'John', 'Matt'],
'Age': [23, 45, 35, 64],
'Birth City': ['London', 'Paris', 'Toronto', 'Atlanta'],
'Gender': ['F', 'F', 'M', 'M']
}
)
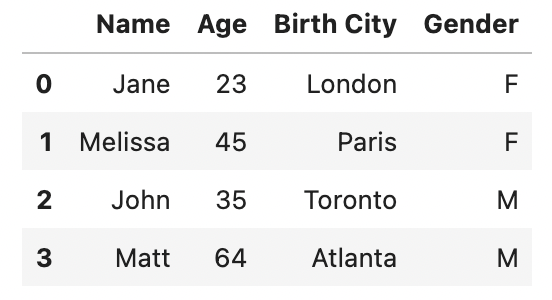
І подивимося, що є в цьому датафреймі
df
Використання Pandas.loc для встановлення стовпця в Pandas
Функція Pandas.loc неймовірно потужна! Ось дуже гарна стаття з loc з розбором цієї функції. Pandas loc створює Булеву маску на основі умови. Іноді цією умовою може бути просто вибір рядків і стовпців, але її також можна використовувати для фільтрації даних. До цих відфільтрованих рамок даних можуть бути застосовані значення
Cинтаксис:
df.loc[df[‘column’] condition, ‘new column name’] = ‘value if condition is met’
Використовуючи синтаксис вище, ми фільтруємо датафрейм за допомогою .loc, а потім привласнюємо значення будь-якому рядку в стовпці (або стовпцях), де виконується умова.
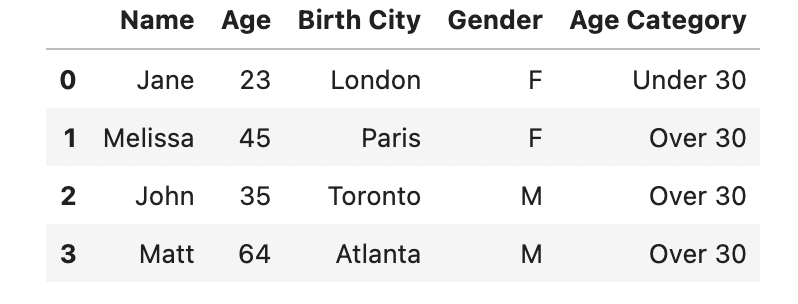
Спробуймо це зробити — присвоївши рядок 'Under 30' усім, чий вік менший за 30 років, а 'Over 30' — усім, кому 30 або більше:
df['Age Category'] = 'Over 30' df.loc[df['Age'] < 30, 'Age Category'] = 'Under 30'
Результат:
Погляньмо, що ми зробили:
- Ми присвоїли рядок 'Over 30' кожному запису в датафреймі.
- Потім ми використовуємо .loc для створення булевої маски на стовпці Age, щоб відфільтрувати рядки, в яких вік менше 30 років. Коли ця умова виконується, стовпчику Вікова категорія присвоюється нове значення 'Under 30'.
Але що відбувається, коли у вас кілька умов? Можна, звичайно, використовувати .loc кілька разів, але це складно для читання і досить неприємно для написання. Давайте подивимося, як це можна зробити за допомогою методу numpy .select ().
Використання Numpy Select для встановлення значень за допомогою декількох умов
Аналогічно описаному вище методу використання .loc для створення умовного стовпця в Pandas, ми можемо використовувати метод numpy .select ().
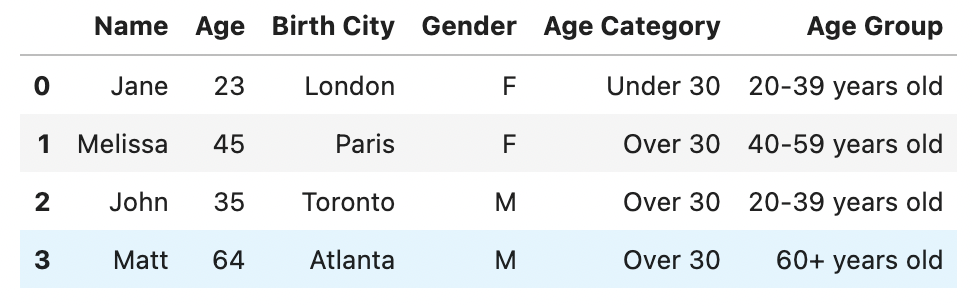
Тепер, припустимо, ми хочемо застосувати кілька різних вікових груп, як показано нижче:
- <20 years old,
- 20-39 years old,
- 40-59 years old,
- 60+ years old
Для цього створимо список умов і відповідних значень для заповнення:
conditions = [
(df['Age'] < 20),
(df['Age'] >= 20) & (df['Age'] < 40),
(df['Age'] >= 40) & (df['Age'] < 59),
(df['Age'] >= 60)
]
values = ['<20 years old', '20-39 years old', '40-59 years old', '60+ years old']
df['Age Group'] = np.select(conditions, values)
Результат:
Розберімо, що відбувається:
- Спочатку ми визначаємо список умов, у якому вказані критерії. Слід зазначити, що списки є впорядкованими, тобто вони повинні розташовуватися в тому порядку, в якому ви хотіли б бачити відповідні значення.
- Потім ми визначаємо список значень, який відповідає значенням, які ви хотіли б застосувати в новому стовпці.
Я у своїй звичайній практиці використовую саме ці методи, ось стаття, в якій ще розглянуто варіанти з Apply і Map