Pandas решение проблемы SettingWithCopyWarning
Описание датасетов
Датасет 1 (dataset-users_emails) — USER_ID, EMAIL. В нем USER_ID пользователя из CRM и EMAIL (далее будет выступать как ключ связки).
Датасет 2 (dataset-emails_phones) — EMAIL, PHONE. Это набор данных, которые мы собирали из различных источников, целевой колонкой для бизнеса номер телефона.
Задача — объеденить два датасета, импортировать полученный датасет в CRM и далее контакт центр должен прозвонить этих клиентов.
Подготовка — перед решением задачи нужно обработать датасет 2 так как в нем телефоны были все в разнобой. Основная подготовка — это привести телефон в один формат — 380XXXXXXXXX.
Импорт библиотек и чтение датасетов:
import pandas as pd
import numpy as np
import re
df_users = pd.read_csv('dataset-users_emails.csv')
df_phones = pd.read_csv('dataset-emails_phones.csv')
Очистка телефонов от всего лишнего при помощи библиотеки re:
df_phones['PHONE'] = df_phones['PHONE'].map(lambda x: re.sub(r'\W+', '', x))
Когда телефоны очищены от спец-символов, пробелов и прочих знаков нужно понять телефоны валидны или нет. Что-то очень сложное с валидацией я не стал проворачивать, а просто проверил на кол-во символов при помощи np.where и если телефон не валиден в колонку is_valid вставил 1, если нет 0:
df['is_valid'] = np.where(df['PHONE'].str.len() == 12, 1, 0)
Далее нужно определить сколько валидных телефонов, а сколько нет. Для этого использовал просто groupby:
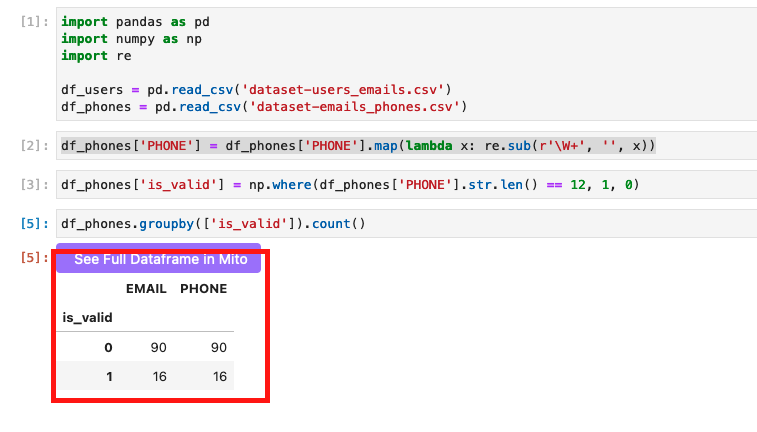
Далее, нужно было обработать невадидные телефоны.
Я предварительно изучил какие там форматы и что мне нужно было сделать)
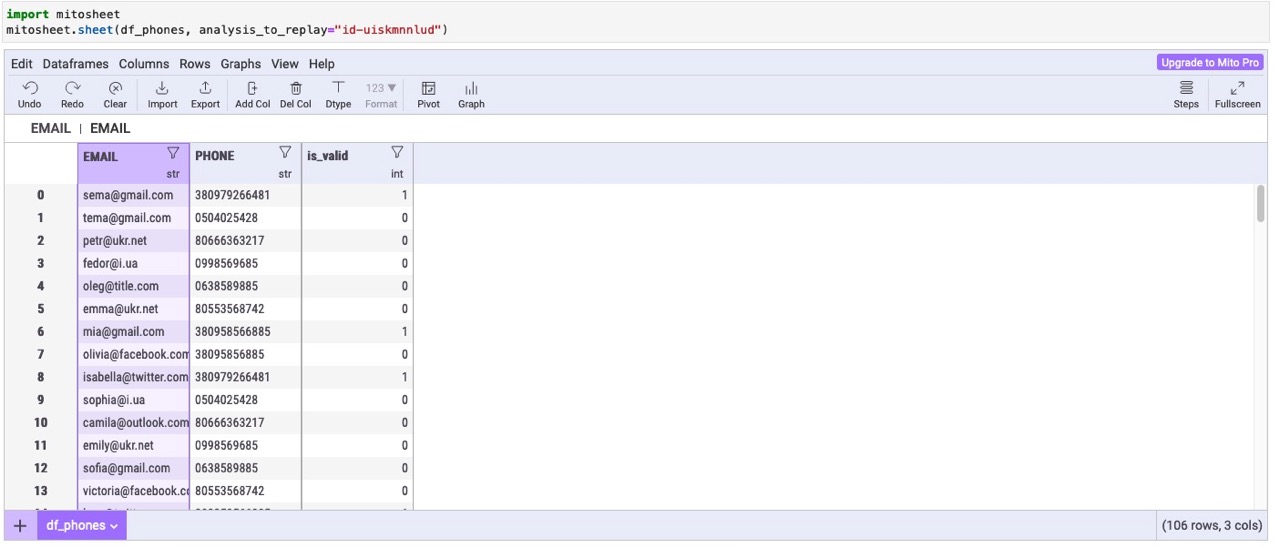
Основная проблема с телефонами была в том, что там были 8 в начале строк, или же не хваталов 380. Дай думаю легко и просто выполню команду и почищу данные:
df_phones[
(df_phones['is_valid'] == 0)
& (df_phones['PHONE'].str.get(0) == '8')
]['PHONE'] = df_phones['PHONE'].str.replace('8','')
Выполнив команду, получил ошибку (или предупреждение) SettingWithCopyWarning:
/var/folders/qt/mx5djmn92sv0v_d1lll28ffm0000gn/T/ipykernel_32045/633074573.py:1: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
Это предупреждение возникает, когда мы пытаемся выполнить присваивание с использованием цепной индексации, поскольку цепная индексация имеет непредсказуемые результаты. Решение проблемы я нашел в этой статье, если вам интересно то можете изучить подробнее.
Для решения проблемы SettingWithCopyWarning можно испольовать функцию pandas — .loc:
Здесь я удалил лишнюю 8 сначала строки, чтобы у меня телефон получился в формате XXXXXXXXXX
df_phones.loc[(df_phones["is_valid"] == 0 ) & (df_phones['PHONE'].str.get(0) == '8'), 'PHONE'] = df_phones['PHONE'].str.replace('8','')
Далее таким-же способом добавляются 38 к строке.
df_phones.loc[df_phones["is_valid"] == 0, "PHONE"] = '38' + df_phones['PHONE']
И еще раз функция валидации (код выше). Из оставшегося массива все что не валидно — обрабатывается руками или придумается другой способ 🙂
На этом у меня все. Если у вас будут вопросы, пишите с радостью обсудил бы 🙂