Pivot — Rows to Columns в SQL
Перепечатка с сайта https://modern-sql.com/use-case/pivot . Также вот полезная статья https://vc.ru/dev/157421-postroenie-svodnyh-tablic-v-sql и еще https://habr.com/ru/post/506070/
Переводить не хочу... Оставляю как заметку для себя.
Pivot или Сводная таблица — инструмент обработки данных, служащий для их обобщения.
Данный Pivot мне необходим был для постоения визуальной аналитики в google data studio. .
Pivoting data is a rather common problem that comes in many different flavors. At its heart, the requirement is to transpose data from multiple rows into columns of a single row.
This requirement is particularity common in a reporting context. The following explanation is therefore based on a query that reports monthly revenues:
SELECT EXTRACT(YEAR FROM invoice_date) year
, EXTRACT(MONTH FROM invoice_date) month
, SUM(revenue) revenue
FROM invoices
GROUP BY EXTRACT(YEAR FROM invoice_date)
, EXTRACT(MONTH FROM invoice_date)The query returns the result in a purely vertical form—one value per row. Quite often, the data is required in another form: for example, just one row per year and a separate column for each month. In other words, the rows of a year should be turned into columns.
The first step in implementing this requirement is to remove the month from the group by and select clauses to get one row per year:
SELECT EXTRACT(YEAR FROM invoice_date) year
, SUM(revenue) total_revenue
FROM invoices
GROUP BY EXTRACT(YEAR FROM invoice_date)Obviously, the result not longer provides a monthly breakdown, nevertheless, this step is required to condense the result to a single row per year.
The next step is to define twelve columns where each column summarizes the revenues of one month only. To get the revenue for January, for example, the expression sum(revenue) must take only invoices from January into account. This can be easily accomplished with the filter clause:
sum(revenue) <b>FILTER (WHERE EXTRACT(MONTH FROM invoice_date) = 1)</b>The filter clause limits the rows aggregated to those satisfying the condition in parenthesis. In this example, only the invoices from January. The revenues of the other months can be obtained in the same way.
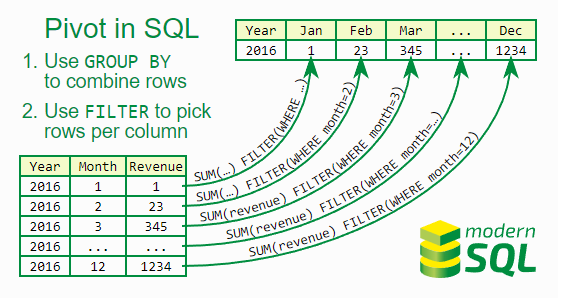
To make the query more literate, the extract expression can be moved to a central location. That could be a generated column or a view so that other queries could reuse this expressions. For this example, it is sufficient to centralize the extract expression within the query—either using the with clause, or as an inline view:
SELECT year
, SUM(revenue) FILTER (WHERE <b>month = 1</b>) jan_revenue
, SUM(revenue) FILTER (WHERE <b>month = 2</b>) feb_revenue
<span class="ellipsis">...</span>
, SUM(revenue) FILTER (WHERE <b>month = 12</b>) dec_revenue
FROM (SELECT invoices.*
<b> , EXTRACT(YEAR FROM invoice_date) year
, EXTRACT(MONTH FROM invoice_date) month</b>
FROM invoices
) invoices
GROUP BY yearConforming Alternatives
Even though the filter clause was introduced with SQL:2003, it is hardly supported today. Luckily, this is not a big problem because <a href="/feature/case">case</a> can be used for the very same purpose. The trick is to map values that do not satisfy the filter criteria to neutral values, which do not change the result of the aggregation. Null is a very good choice for this because it does not change the result of any aggregate function—not even avg. Furthermore, else null is the default clause for case expressions without explicit else clause anyway—it is sufficient to skip the else clause altogether.
SELECT year
, SUM(CASE WHEN <b>month = 1</b> THEN revenue END) jan_revenue
, SUM(CASE WHEN <b>month = 2</b> THEN revenue END) feb_revenue
<span class="ellipsis">...</span>
, SUM(CASE WHEN <b>month = 12</b> THEN revenue END) dec_revenue
FROM (SELECT invoices.*
<b> , EXTRACT(YEAR FROM invoice_date) year
, EXTRACT(MONTH FROM invoice_date) month</b>
FROM invoices
) invoices
GROUP BY yearThe expression CASE WHEN month = 1 THEN revenue END evaluates to the revenue for invoices from January. For other invoices, the implied else null returns the null value, which does not change the result of sum. See also “Null in Aggregate Functions (count, sum, …)” and “Conforming Alternatives to filter”.
On my Own Behalf
I make my living from training, other SQL related services and selling my book. Learn more at https://winand.at/.
The Special Case of EAV
The greatest challenge with the pivot problem is to recognize it when you run into it. This is particularity true when dealing with the so-called entity-attribute-value (EAV) model: it does not look like a pivot problem, but it can nevertheless be solved in the very same way.
The EAV model takes normalization to the extreme and no longer uses columns in the traditional way. Instead, every single value is stored in its own row. Besides the value, the row also has a column to specify which attribute the value represents and a third column to identify what entity the values belongs to. Ultimately, a three column table can hold any data without ever needing to change the table definition. The EAV model is thus often used to store dynamic attributes.
The EAV model does not come without drawbacks: It is almost impossible to use constraints for data validation, for example. However, the most puzzling issue with the EAV model is that the transformation into a one-column-per-attribute notation is almost always done using joins—quite often one outer join per attribute. This is not only cumbersome, it also results in very poor performance—a true anti-pattern.
However, turning rows into columns is the pivot problem in its purest form. Therefore, these steps should be followed again: (1) use group by to reduce the rows to one row per entity, (2) use <a href="/feature/filter">filter</a> or <a href="/feature/filter#conforming-alternatives">case</a> to pick the right attribute for each column.
SELECT submission_id
, MAX(CASE WHEN attribute='name' THEN value END) name
, MAX(CASE WHEN attribute='email' THEN value END) email
, MAX(CASE WHEN attribute='website' THEN value END) website
FROM <span class="quoted-table-identifier">form_submissions</span>
GROUP BY submission_idNote the use of the max function: it is required to reduce the rows of the group (all attributes) into a single value. This is a purely syntactic requirement that is applicable regardless of the actual number of rows that are grouped.
To obtain the original value for each attribute—even though we have to use an aggregate function—the respective filter logic (case or filter) must not return more than one not-null value. In the example above, it is crucial that each of the named attributes (name, email, website) exists only once per submission_id. If duplicates exist, the query returns only one of them.
The prerequisite that each attribute must not appear more than once is best enforced by a unique constraint.0 Alternatively, the query can count the aggregated rows using count(*) and the respective case expressions (or filter clauses). The results can be validated in the application—if selected as additional columns—or in the having clause: having count(*) filter (...) <= 1.
If the prerequisite is satisfied and the aggregation is always done on a single not-null value, every aggregate function just returns the input value. However, min and max have the advantage that they also work for character strings (char, varchar, etc.).
Limitations
SQL is a statically typed language: the query must list the result columns upfront. To pivot a table with unknown or dynamic attributes, multisets or document types (XML, JSON) can be used to represent a key-value store in a single column. See conforming alternatives to listagg: document types.
Compatibility
BigQueryDb2 (LUW) MariaDBMySQLaOracle DBPostgreSQLSQL ServerSQLitefilter clausecase
- The
filter_pluginextension (3rd party) rewritesfiltertocaseusing regular expressions
Proprietary Alternatives
pivot and unpivot (SQL Server, Oracle)
SQL Server supports the pivot and unpivot clauses since version 2005 (documentation). They are also available in the Oracle Database since version 11g (documentation).
model clause (Oracle)
The proprietary model clause, which was introduced with Oracle Version 10g, can also be used to solve the pivot problem (documentation).
crosstab table function (PostgreSQL)
The PostgreSQL database is delivered with a set of crosstab table functions to pivot data (documentation).