Як The New York Times використовує машинне навчання, щоб зробити свою платну платформу розумнішою
Зміст
У березні 2011 року The New York Times почала пропонувати платні послуги. Вони запровадили систему, де НЕпередплатники можуть читати обмежену кількість статей на місяць перед тим, як потрібно буде платити. Це називалося «meter limit». Ця стратегія дозволяла привернути платних користувачів і давала новим користувачам можливість ознайомитися з контентом. У лютому 2022 року The Times досягли своєї мети — 10 мільйонів платних підписників, а до 2027 року планують досягти 15 мільйонів. Цей успіх став можливим завдяки постійному вдосконаленню стратегії платної підписки. Спочатку «meter limit» був однаковим для всіх, але згодом The Times змогли використати модель каузального машинного навчання під назвою «Dynamic Meter», щоб встановлювати персоналізовані ліміти для користувачів, оскільки вони перетворилися на цифрову компанію, яка працює з даними.
Стратегія paywall
Стратегія платного доступу (paywall) в The Times ґрунтується на концепції воронки підписки:
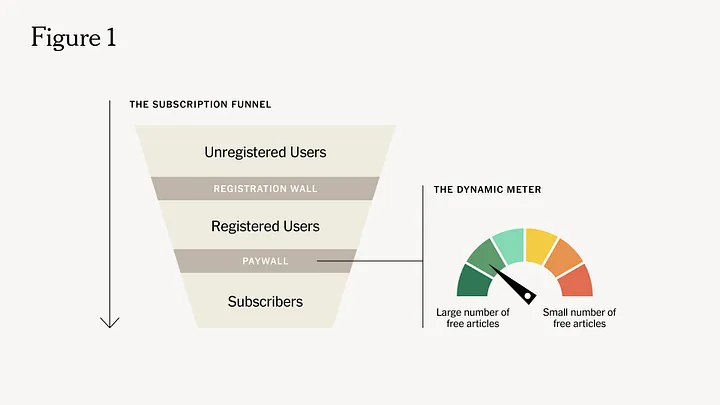
У верхній частині воронки знаходяться незареєстровані користувачі, які ще не мають облікового запису в The Times. Коли вони досягають свого ліміту, вони бачать вікно реєстрації (registration-wall/login-wall), яка блокує доступ і просить їх створити обліковий запис або увійти в систему, якщо вони вже мають обліковий запис. Це дає їм доступ до більшої кількості безкоштовного контенту. Оскільки їхня активність пов'язана з їхнім реєстраційним ідентифікатором, це дозволяє краще зрозуміти їхній поточний інтерес до контенту The Times.
Ця інформація про користувача є цінною для будь-якої програми машинного навчання і також служить основою для роботи моделі «Dynamic Meter». Коли зареєстровані користувачі досягають свого ліміту, вони отримують пропозицію оформити передплату (pay-wall). Саме на цьому етапі модель «Dynamic Meter» приймає управління. Вона навчається на основі зовнішніх даних про активність зареєстрованих користувачів і визначає відповідний ліміт, щоб оптимізувати один або кілька ключових показників ефективності бізнесу (K.P.I. — Key Performance Indicators).
Для чого оптимізується «Dynamic Meter»?
Модель «Dynamic Meter» виконує подвійну функцію. Вона має підтримувати місію The Times допомагати людям розуміти світ і одночасно забезпечувати бізнес-ціль залучення передплатників. Це досягається шляхом оптимізації двох метрик одночасно: залучення зареєстрованих користувачів до контенту The Times та кількості передплат, які генерує платний доступ до статей протягом певного періоду часу.
Ці дві метрики мають свою внутрішню компромісну залежність, оскільки більше платних доступів зазвичай веде до більшої кількості передплат, але це може призвести до зменшення числа читачів статей. Цей компроміс видно на основі зібраних даних з контрольованого випадкового експерименту (RCT), як показано на рисунку Figure 2. Зі збільшенням ліміту для зареєстрованих користувачів зростає залучення, виміряне середньою кількістю переглядів сторінок. Це супроводжується зменшенням відсотку конверсії на передплати, головним чином через зменшену кількість зареєстрованих користувачів, які зустрічають платний доступ. З іншого боку, більша кількість обмежень (tighter meter limits) також впливає на звичку читачів і може знизити їхній інтерес до контенту. Це в свою чергу впливає на потенціал перетворення їх у передплатників на довготривалий період. В основному, модель «Dynamic Meter» має оптимізувати конверсію і залучення, збалансовуючи між ними компроміс.

Dynamic Meter — це прескриптивна модель машинного навчання.
Метою цієї моделі є встановлення лімітів доступу до статей з обмеженого набору варіантів, які доступні. Таким чином, модель повинна виконати дію, яка вплине на поведінку користувача і вплине на результат, такі як його схильність до передплати та взаємодія з контентом The Times. На відміну від прогностичної моделі машинного навчання, для прескриптивних задач рідко відома «істинна» інформація. Іншими словами, якщо користувачу було встановлено ліміт доступу «а», ми не знаємо, що сталося б з цим користувачем, якби йому був встановлений інший ліміт «б» протягом того ж часового періоду. Ця проблема іноді називається «фундаментальною проблемою причинної інференції» або просто «проблемою відсутніх даних». Краще, що ми можемо зробити, — це оцінити, що сталося б, використовуючи дані інших користувачів, яким був встановлений ліміт «б». Це підкреслює важливість даних, зібраних з контрольованого випадкового експерименту (RCT), оскільки вони є необхідними для тренування моделі.
Як працює модель?
Для оптимізації ставиться дві цілі: схильність до передплати і залучення користувачів. Для цього ми тренуємо дві моделі машинного навчання, які називаємо «базовими моделями» (Рівняння 1). Структура цих базових моделей схожа на популярну мета-модель, відому як «S-learner». Така модель передбачає цільову змінну, використовуючи характеристики X і змінну обробки T. У нашому випадку, змінна обробки T є категоріальною змінною, яка вказує ліміт доступу, наданий кожному зареєстрованому користувачеві. Характеристики визначаються виключно з власних даних про їх залученість до контенту The Times. Ми не використовуємо жодних демографічних або психографічних характеристик в моделі, щоб уникнути несправедливих упереджень проти захищених категорій (ми зобов'язані використовувати машинне навчання в The Times чесним та відповідальним способом; ви можете ознайомитися з обговоренням нашого підходу до машинного навчання щодо модерації коментарів тут).
За допомогою даних R.C.T. для користувачів з характеристиками X і відповідною змінною обробки T, ми можемо побудувати дві моделі машинного навчання, f і g, які передбачають схильність до передплати (p) та нормалізоване залучення (e) відповідно. Щоб максимізувати обидві ці цілі одночасно, ми перетворюємо їх на одну ціль s за допомогою конвексної лінійної комбінації, вводячи ваговий коефіцієнт δ, який приймає значення від 0 до 1 (Рівняння 2). Він виступає як параметр тертя і дозволяє нам явно встановити важливість, яку ми хочемо приділити передплатам порівняно з залученням. Як тільки встановлено певне значення δ, політика назначає обробку користувачеві, яка максимізує комбіновану цільову функцію s (Рівняння 3). Цю політику можна застосовувати кілька разів для різних значень δ, отримуючи набір оптимальних рішень, які формують критерій Парето. Критерій Парето зазвичай є опуклим і містить рішення, які є кращими, ніж інші, принаймні за однією з цільових функцій, і змінюючи його, одна з цільових функцій зменшується, а інша збільшується.
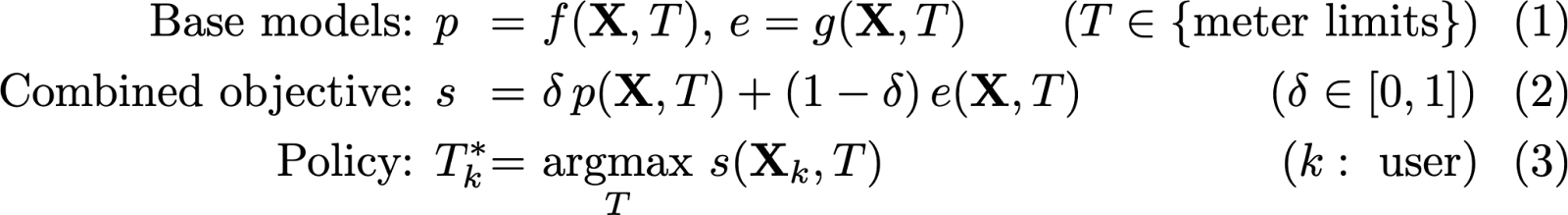
Параметр тертя (friction parameter) в даному контексті використовується для керування важливістю метрик і балансу між ними. Він визначає, наскільки сильно вага надається підпискам порівняно з залученням користувачів.
У тексті зазначено, що параметр тертя, позначений як δ, приймає значення від 0 до 1. Значення 1 вказує, що передплати мають найвищий пріоритет і є єдиною метою оптимізації. З іншого боку, значення 0 означає, що залучення користувачів має найвищий пріоритет, і підписки не розглядаються.
Таким чином, параметр тертя дозволяє контролювати компроміс між двома метриками: передплатами і залученням користувачів. Це дозволяє знайти оптимальний баланс, щоб максимізувати обидві ці цілі одночасно, враховуючи важливість кожної з них.
Для графічного зображення цього давайте припустимо, що ми встановили δ = 1, щоб оптимізувати лише передплати. Використовуючи модель f, для кожного зареєстрованого користувача ми можемо передбачити схильність до передплати в контрфактичних сценаріях, де їм були б надані різні ліміти доступу. Політика потім назначає ліміт доступу, який генерує найвищу схильність до передплати (Рисунок 3). В суті, модель визначає правильну кількість безкоштовних статей, які дозволяються кожному користувачеві, щоб вони достатньо зацікавилися The Times і бажали підписатися, щоб продовжити читати більше.

Як модель тестується на історичних даних?
Перед запуском моделі ми тестуємо її на історичних даних, щоб оцінити її якість після розгортання. Це називається бек-тестуванням, яке передбачає відповідь на питання, як би працювала модель, якби вона була розгорнута в певний момент у минулому. У контексті «Dynamic Meter» треба дізнатися, як би працювала модель, якби вона визначила ліміти для певного минулого місяця. Оскільки неможливо змінити призначення в минулому, треба використати минулі дані R.C.T. і розглянути лише тих користувачів, для яких призначення моделі збіглися з призначенням R.C.T.
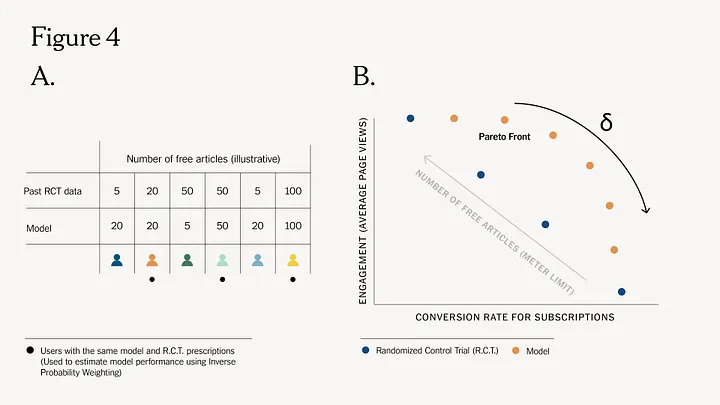
Враховуючи, чи тільки ці користувачі підписалися, можливо оцінити загальний коефіцієнт конверсії (C.V.R.), використовуючи зворотне ймовірнісне зважування та оцінку Хаєка (Рівняння 4). Ця оцінка дає нам C.V.R., який ми могли б очікувати, якби ми дійсно могли повернутися в минуле і встановити ліміти лічильників для всіх користувачів, використовуючи модель. Аналогічну оцінку можна зробити і для отримання середнього перегляду сторінки.

Процедуру оцінки можна повторити, змінюючи параметр коефіцієнта впливу δ, що призведе до набору точок, які утворюють критерій Парето (помаранчеві точки на рисунку Figure 4B). Змінюючи δ від 0 до 1, рахується вздовж фронту, збільшуючи коефіцієнт конверсії та зменшуючи середню кількість переглядів сторінок. Одна з цих точок обирається залежно від того, на який коефіцієнт конверсії необхідно орієнтуватися протягом місяця. В результаті можливо отримати підвищення залученості порівняно з випадковою політикою (сині точки) з тим самим коефіцієнтом конверсії. Таким чином, ця стратегія дозволяє гнучко налаштовувати рівень тертя відповідно до наших бізнес-цілей і в той же час розумно таргетувати користувачів, щоб підвищити рівень залученості та коефіцієнт конверсії порівняно з чисто випадковою політикою.
Переклад статті https://open.nytimes.com/how-the-new-york-times-uses-machine-learning-to-make-its-paywall-smarter-e5771d5f46f8